协议PDF文档分析与测试生成
一种系统化方法,用于从复杂的协议PDF规范中提取、分析并生成结构化测试用例。

概述
系统化协议测试
我们的方法将复杂的协议PDF文档转化为结构化、可执行的测试用例。
协议规范通常以冗长、复杂的PDF文档形式提供,包含文本、表格、图表和图像的混合内容。从这些文档中手动提取可测试的需求既耗时又容易出错,往往导致测试覆盖不一致。
我们的系统提供了一种结构化方法来分析协议PDF文档,过滤相关内容,分解协议逻辑,并以标准化格式生成全面的测试用例。
通过自动化大部分流程,同时保留领域专家的关键作用,我们能够实现更快速、更全面的协议测试,并清晰地追溯到原始规范。
方法论
我们的流程
一种多阶段方法,将复杂文档转化为可执行的测试用例。
文档获取
解析PDF内容,包括文本、表格和图像
内容过滤
识别并提取与协议相关的内容
逻辑分解
按章节、模块和命令进行分解
测试点提取
识别可测试的需求和约束
测试用例生成
以Markdown格式创建结构化测试用例
优势
为什么这种方法很重要
我们的方法解决了协议测试中的关键挑战。
时间效率
大幅减少分析协议文档和创建测试用例所需的时间。
全面覆盖
确保测试中系统地覆盖所有协议方面,降低遗漏风险。
可追溯性
每个测试用例都直接链接到原始规范文档中的来源。
质量保证
标准化方法确保不同协议之间的测试用例一致且高质量。
详细方法论
五个阶段
深入了解我们协议分析流程的每个阶段。
阶段1:PDF文档获取与准备
这个初始阶段专注于将PDF协议文档转换为机器可处理的内容,同时保留其结构。
主要活动:
- 文本提取: 提取所有文本内容,同时保留布局信息
- 表格提取: 识别并提取通常包含关键协议参数的表格
- 图像提取: 捕获图表、流程图和状态机
- 结构识别: 识别文档结构,包括标题、章节和页码
推荐工具:
- PyMuPDF (Fitz): 用于全面的文本和布局提取
- Camelot/Tabula-py: 用于专门的表格提取
- OCR (Tesseract): 用于扫描文档
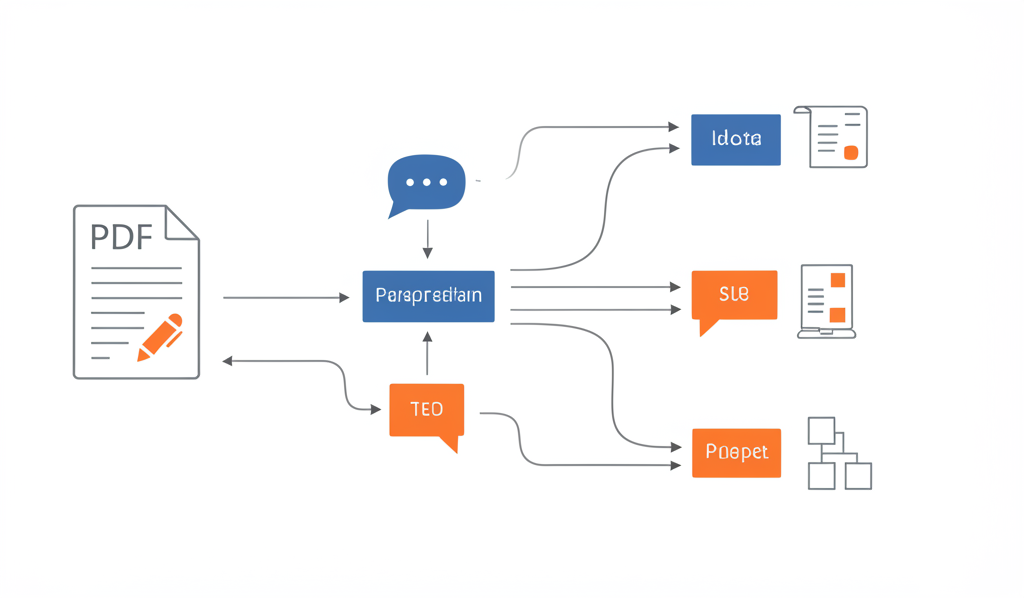
交互式演示
PDF分析过程
探索我们如何将复杂的协议PDF文档转化为结构化测试用例
阶段 1: 文档获取
从PDF文档中提取文本、表格和图像内容
使用PDF解析工具提取文本内容
识别并提取表格数据
捕获图表和流程图
保留文档的结构信息
输入:

输出:

结论
战略建议
实施这种方法论的关键要点和后续步骤。
我们对协议PDF分析和测试用例生成的系统化方法比传统手动方法提供了显著优势。通过将自动化工具与领域专业知识相结合,组织可以实现更全面的测试覆盖,同时减少所需的时间和精力。
关键建议:
- 试点实施: 从特定的协议部分或模块开始,以完善流程
- 工具选择: 根据文档特性选择适当的PDF解析工具
- 迭代改进: 持续改进过滤规则和分解逻辑
- 协作验证: 让领域专家参与审查生成的测试用例
- 集成: 与测试管理和执行系统连接,实现端到端自动化
虽然自动化在这种方法中扮演着关键角色,但人类专业知识对于处理歧义、解释复杂图表以及验证生成的测试用例的相关性和正确性仍然至关重要。
通过采用这种系统化方法,组织可以为协议测试建立坚实的基础,确保更高质量的实现,同时显著减少传统上所需的手动工作。